Practical Aspects of Double Machine Learning
What is Double/Debiased Machine Learning (DML)?
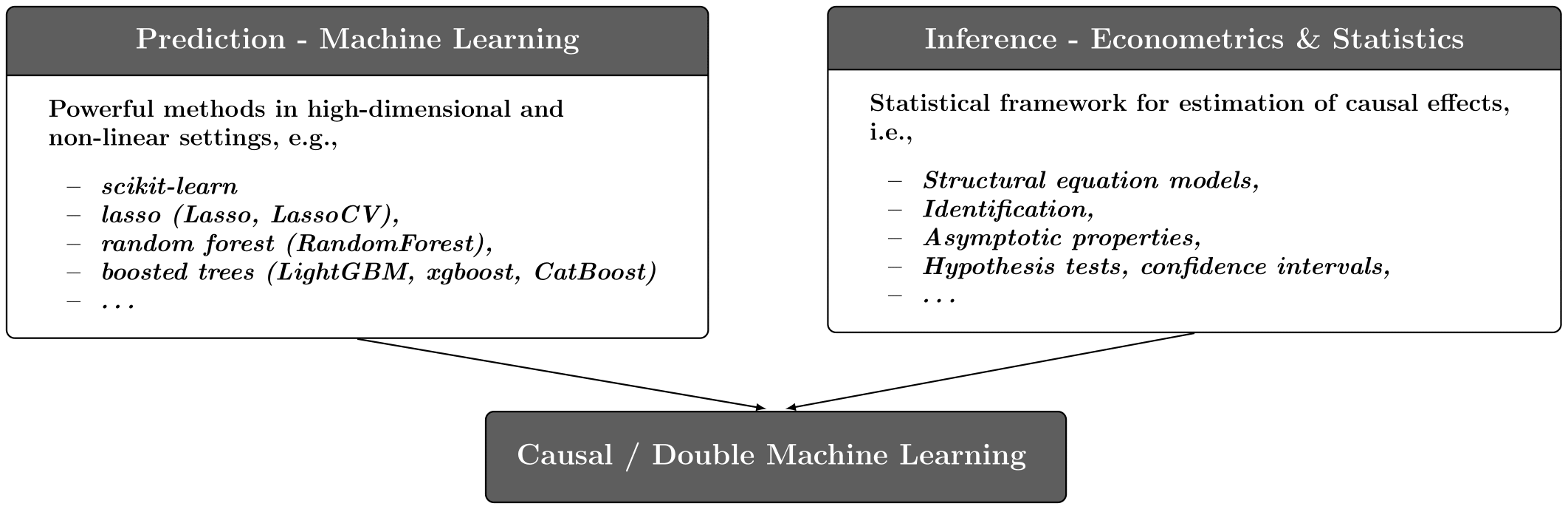
DML is a general framework for causal inference and estimation of causal parameters based on machine learning
Summarized in Chernozhukov et al. (2018)
Combines the strengths of machine learning and econometrics
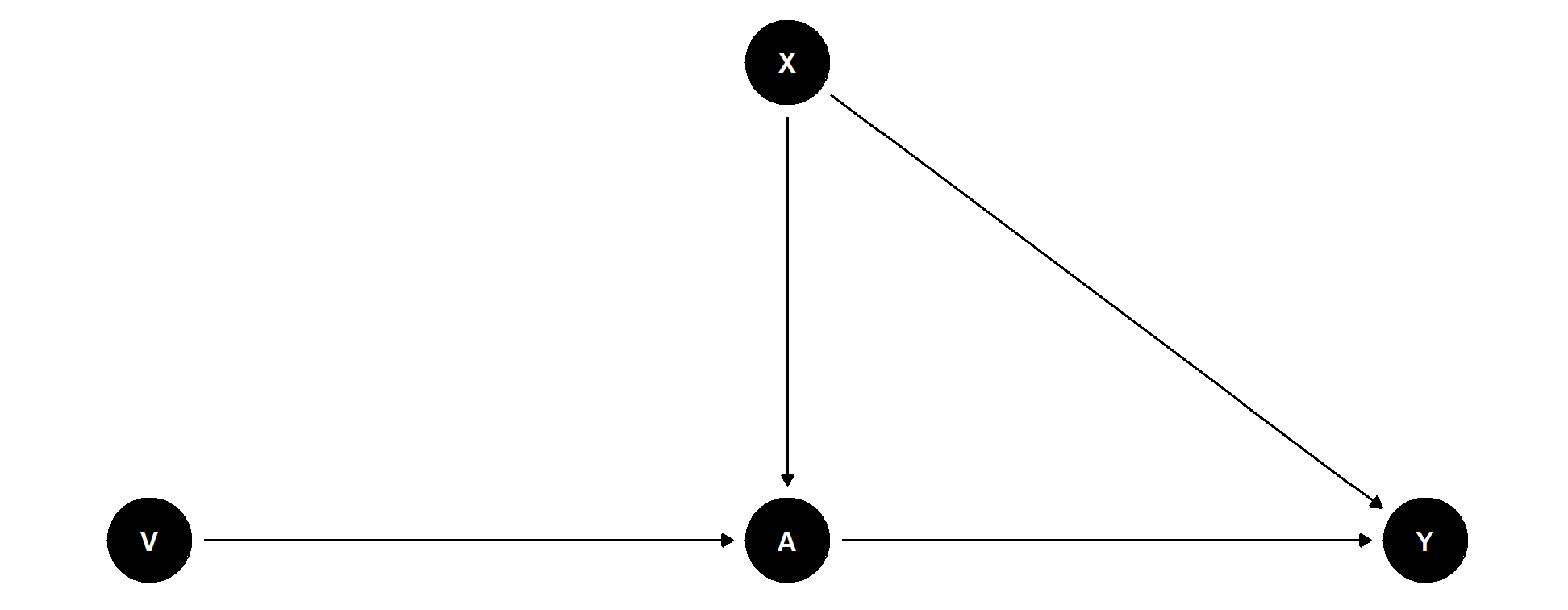
Motivating Example
Partially linear regression model (PLR)
\[\begin{align*} &Y = D \theta_0 + g_0(X) + \zeta, & &\mathbb{E}[\zeta | D,X] = 0, \\ &D = m_0(X) + V, & &\mathbb{E}[V | X] = 0, \end{align*}\]
with
- Outcome variable \(Y\)
- Policy or treatment variable of interest \(D\)
- High-dimensional vector of confounding covariates \(X = (X_1, \ldots, X_p)\)
- Stochastic errors \(\zeta\) and \(V\)
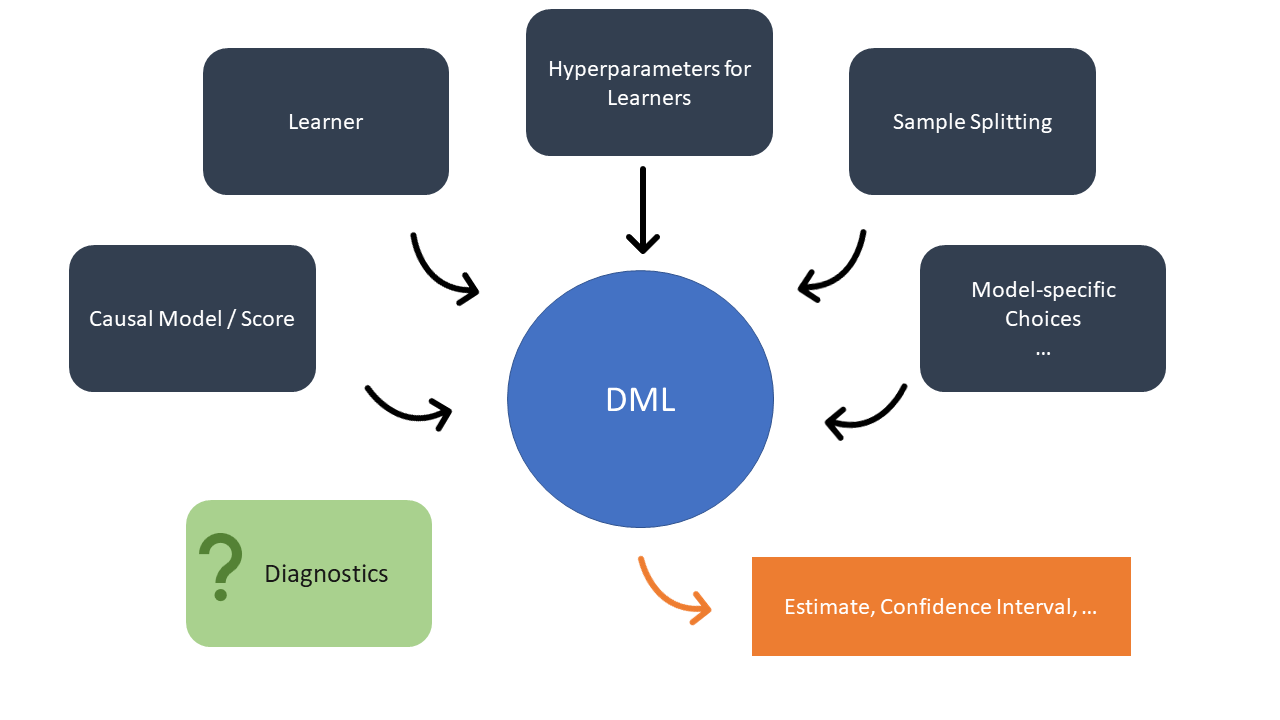
Practical Aspects of DML
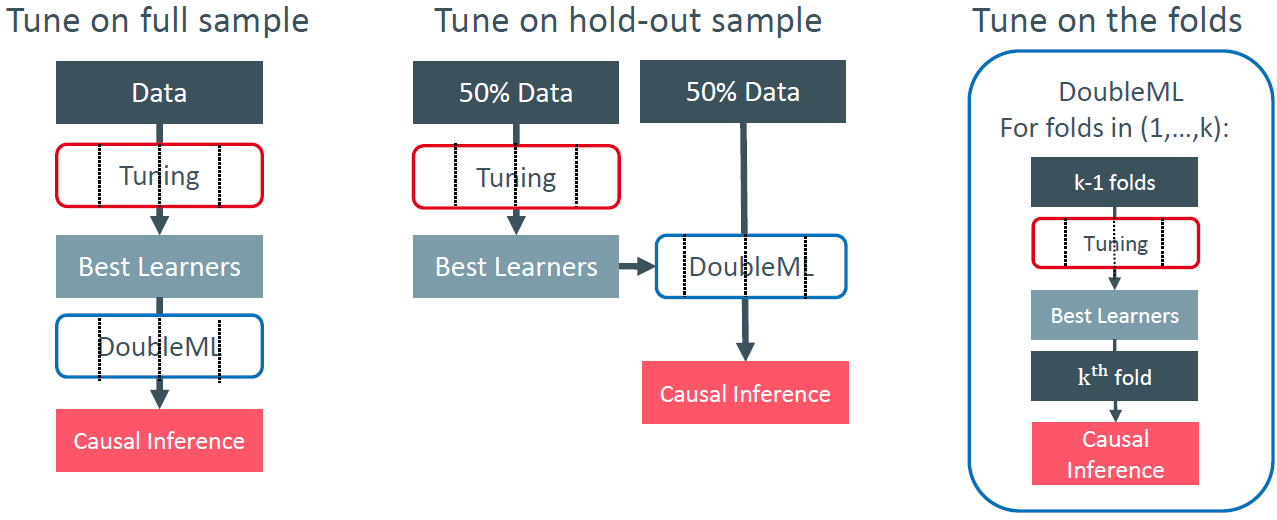
Sample Splitting and Hyperparameter Tuning
Canditate splitting schemes
Simulation Results: 1. BCH 2014
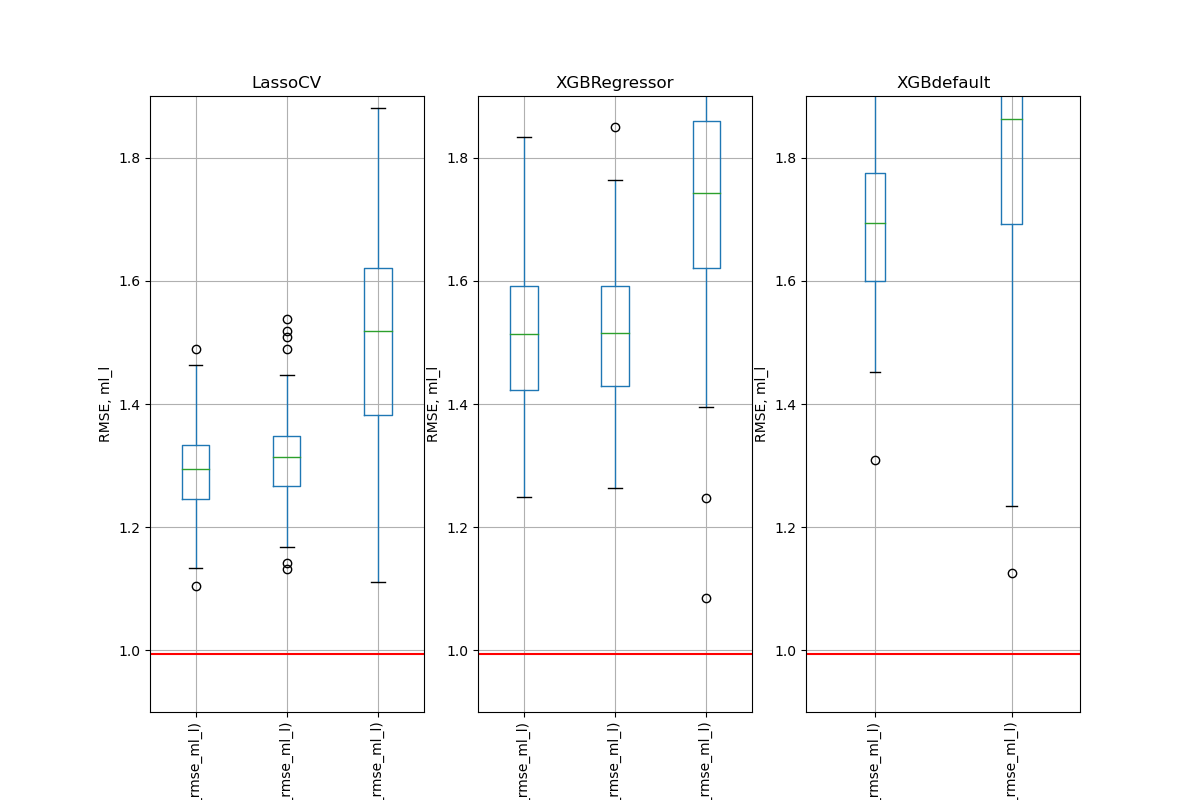
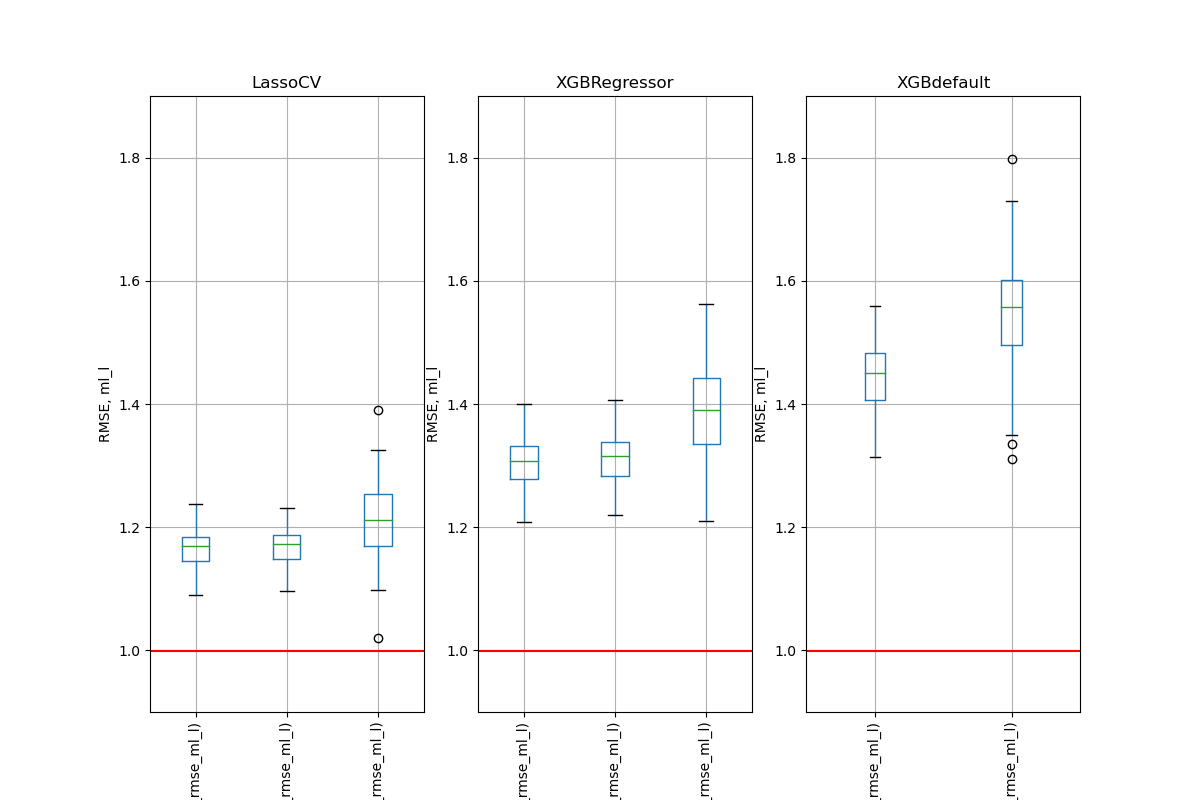
Simulation Results: 1. BCH 2014
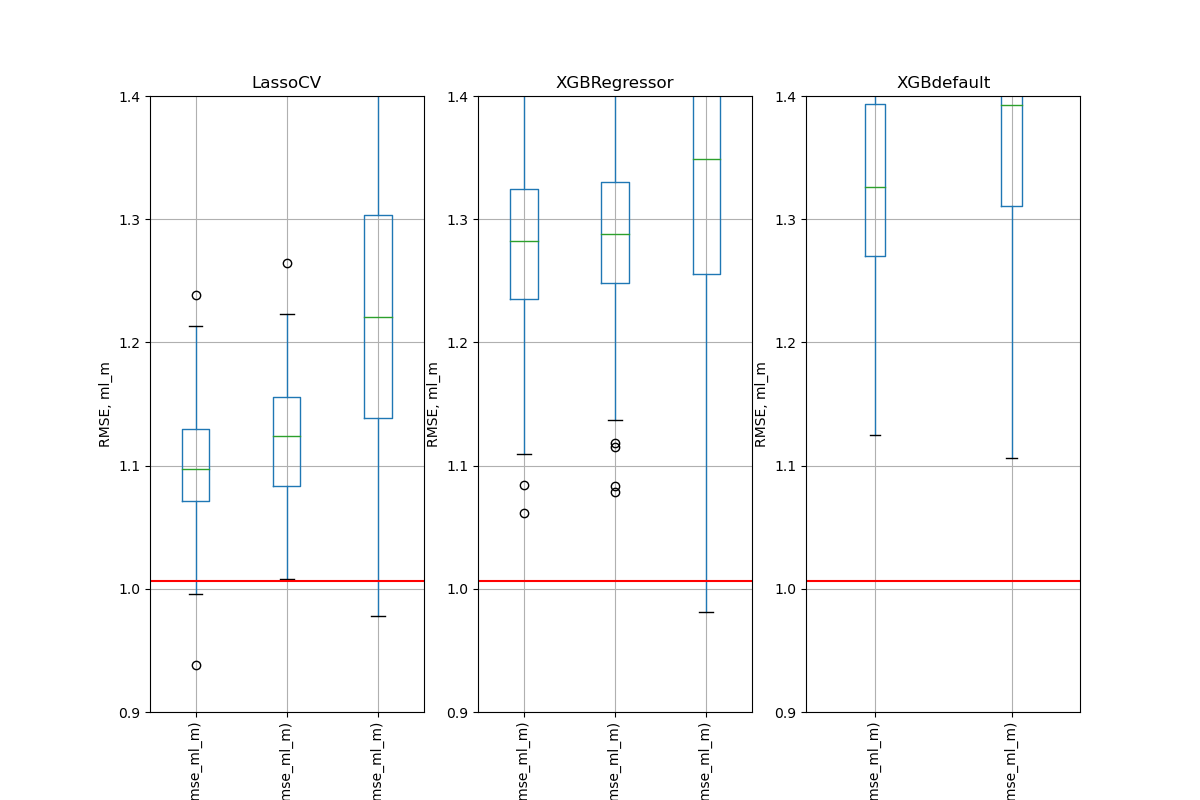
Simulation Results: 1. BCH 2014
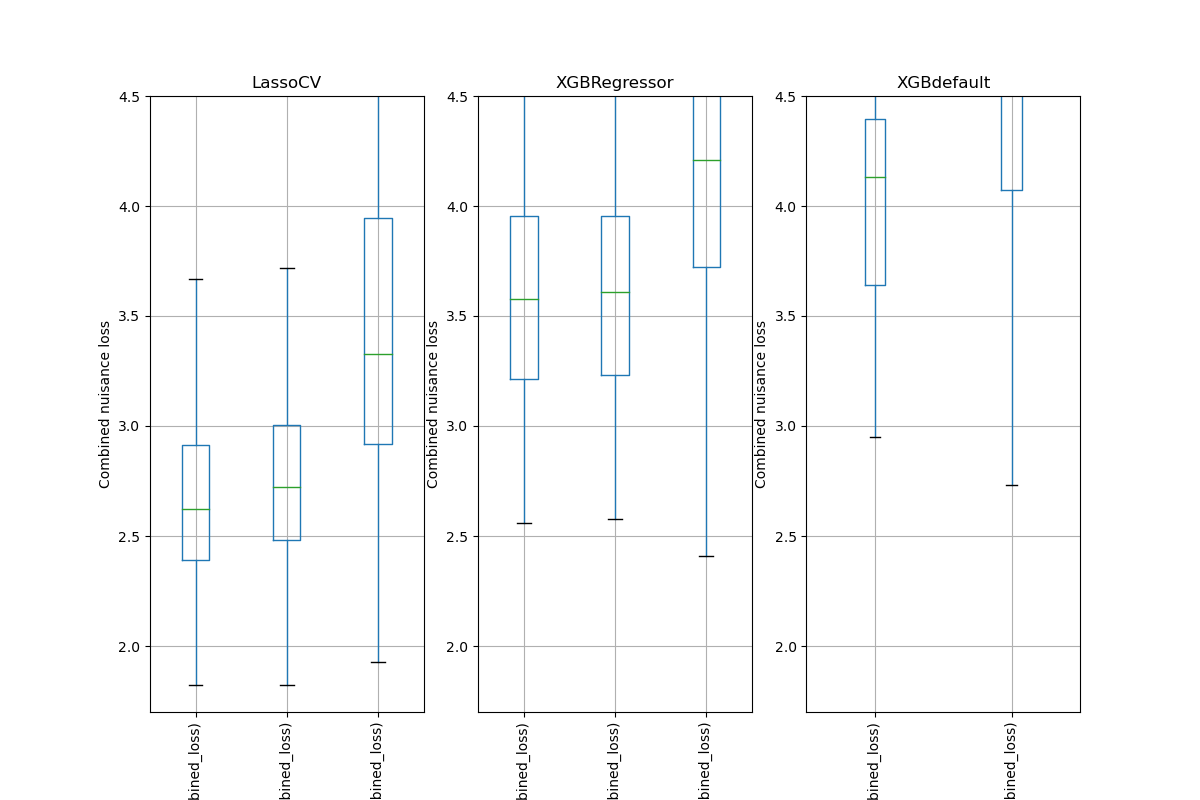
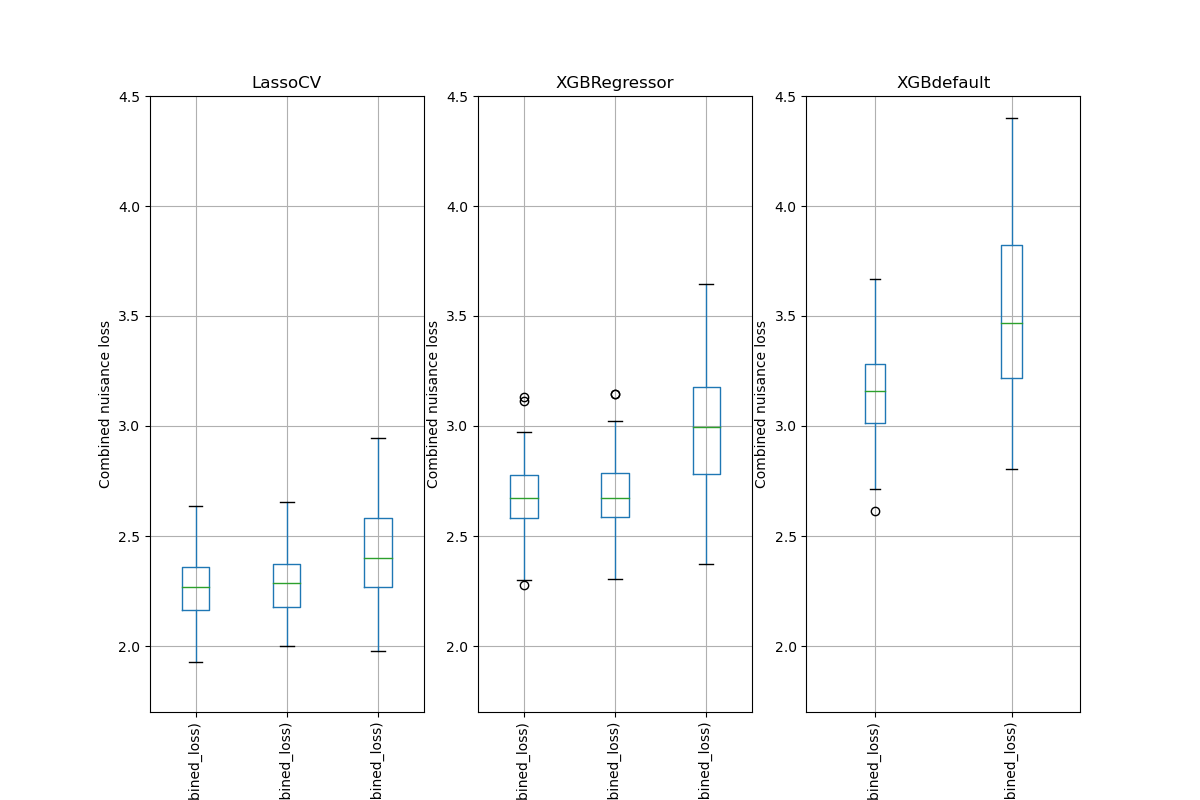
Simulation Results: 1. BCH 2014
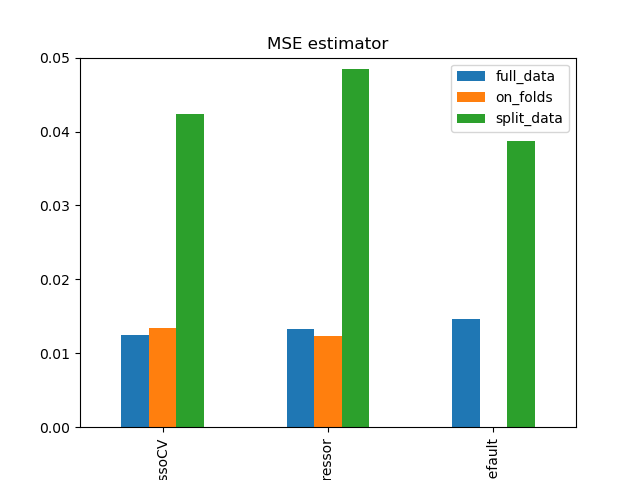
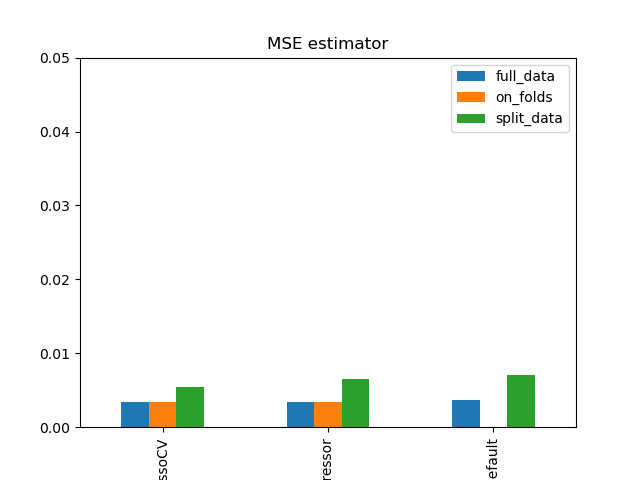
Simulation Results: 1. BCH 2014
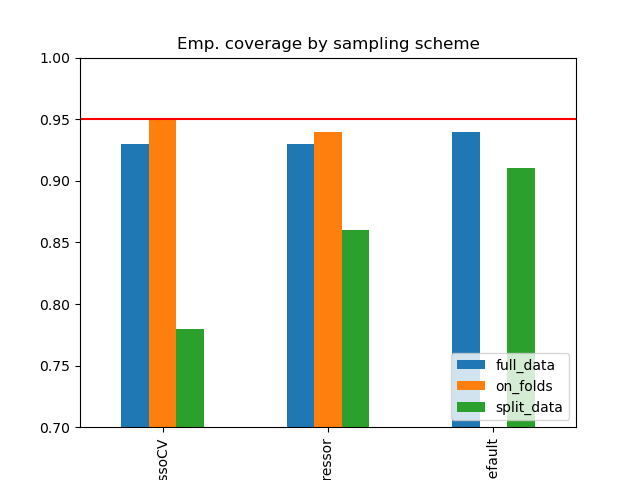
Simulation Results: 1. BCH 2014
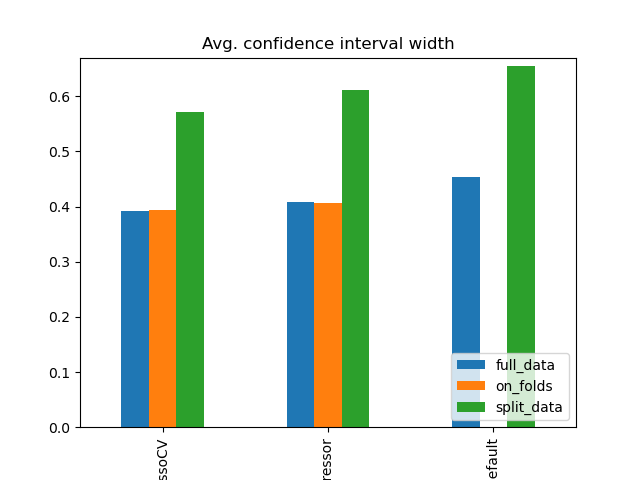
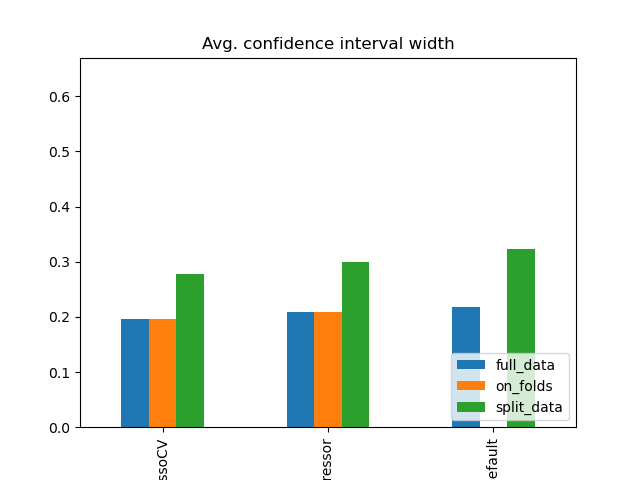
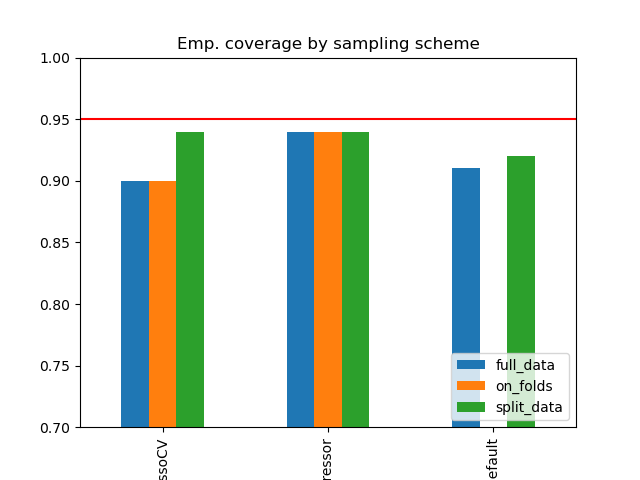
Simulation Results: 1. BCH 2014
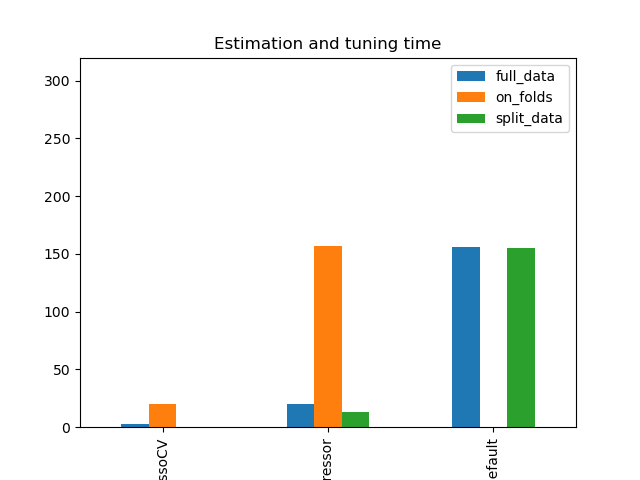
Simulation Results: 1. BCH 2014
Number of Folds for Cross-Fitting
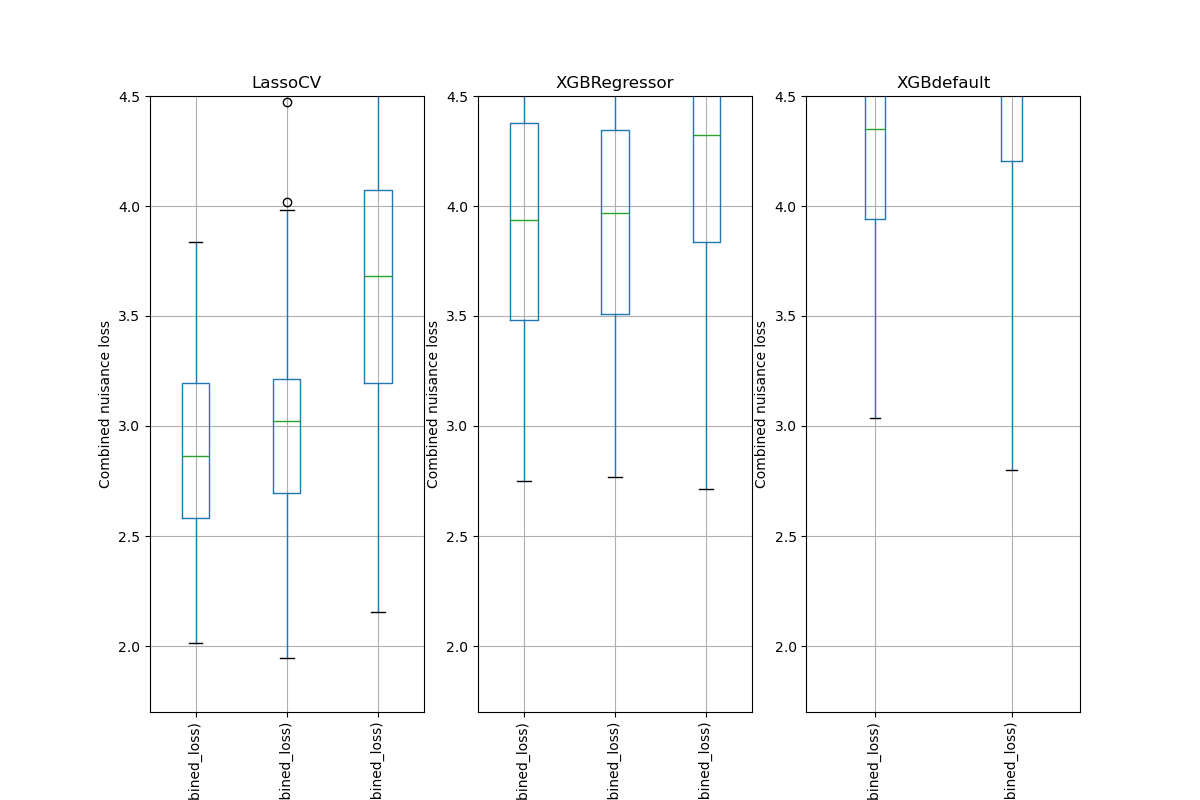
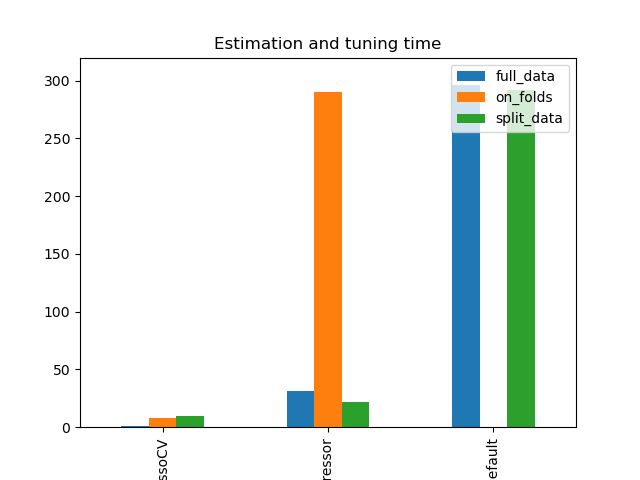
Simulation Results: 1. BCH 2014
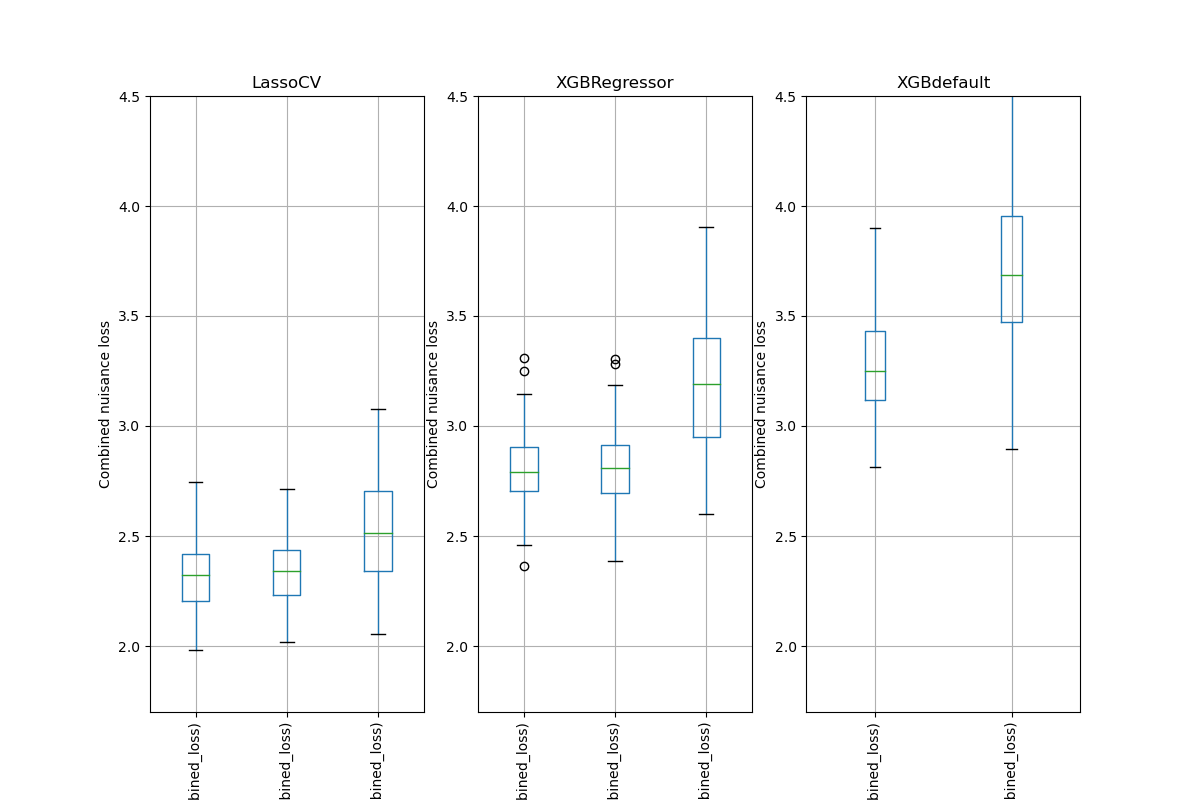
Simulation Results: 1. BCH 2014
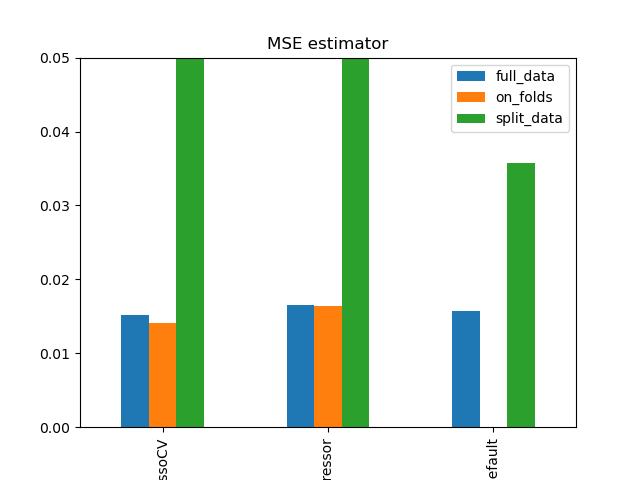
Simulation Results: 1. BCH 2014
Simulation Results: 1. BCH 2014
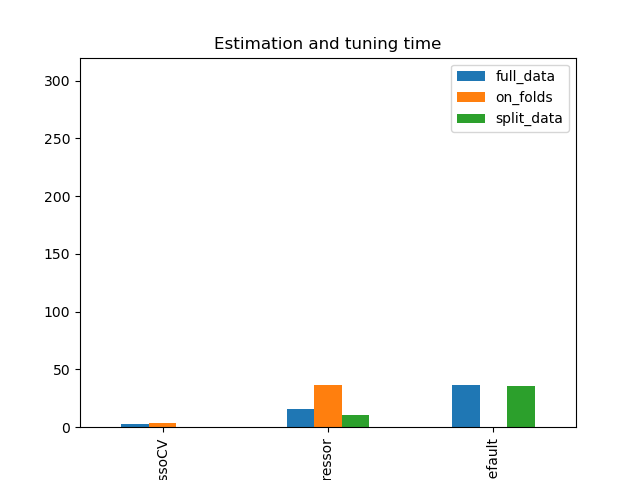
Simulation Results: 1. BCH 2014
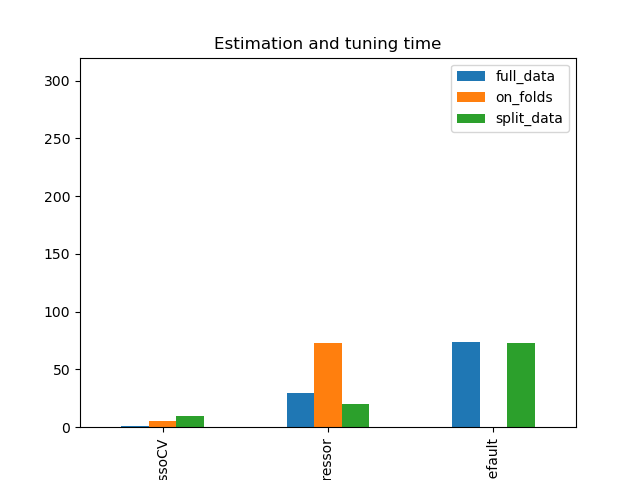
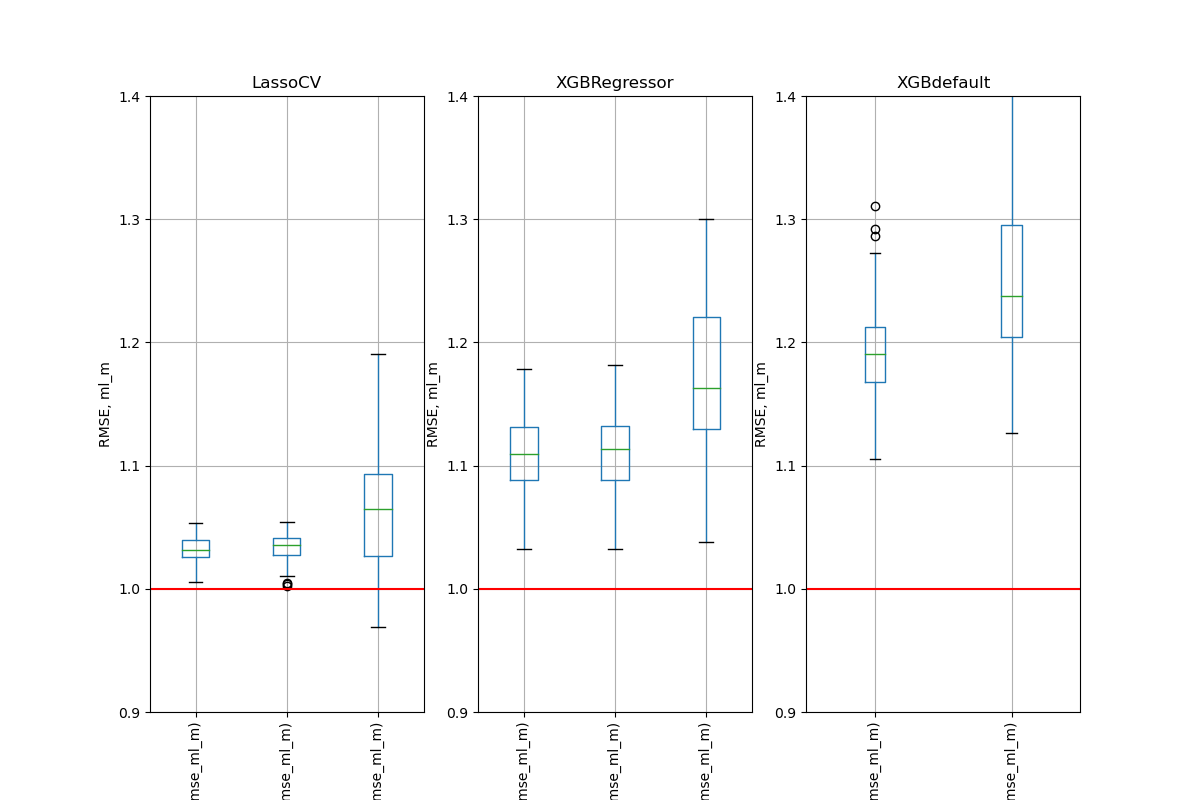
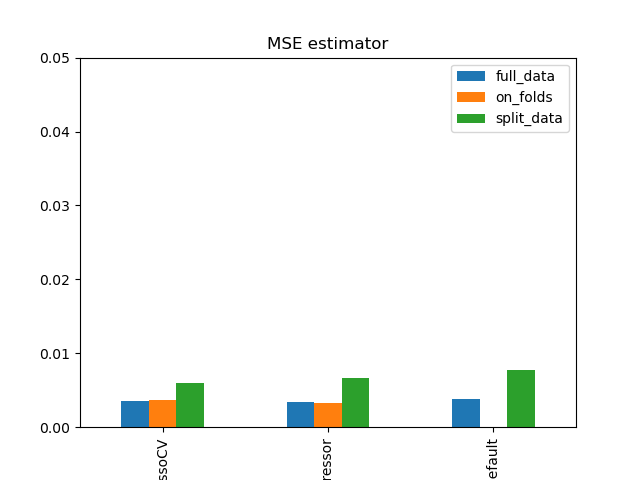
Simulation Results: 2. ACIC (DGP 2)
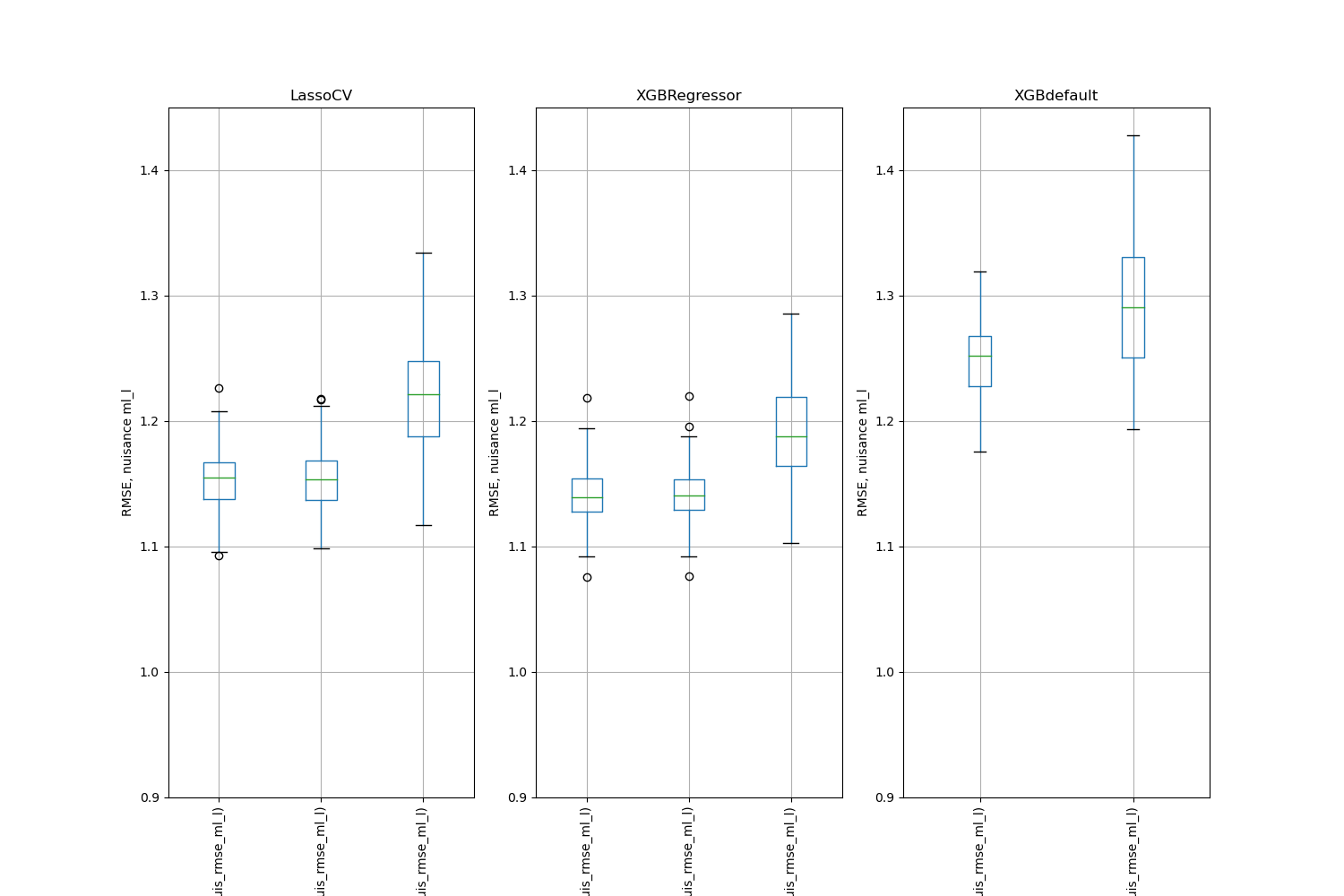
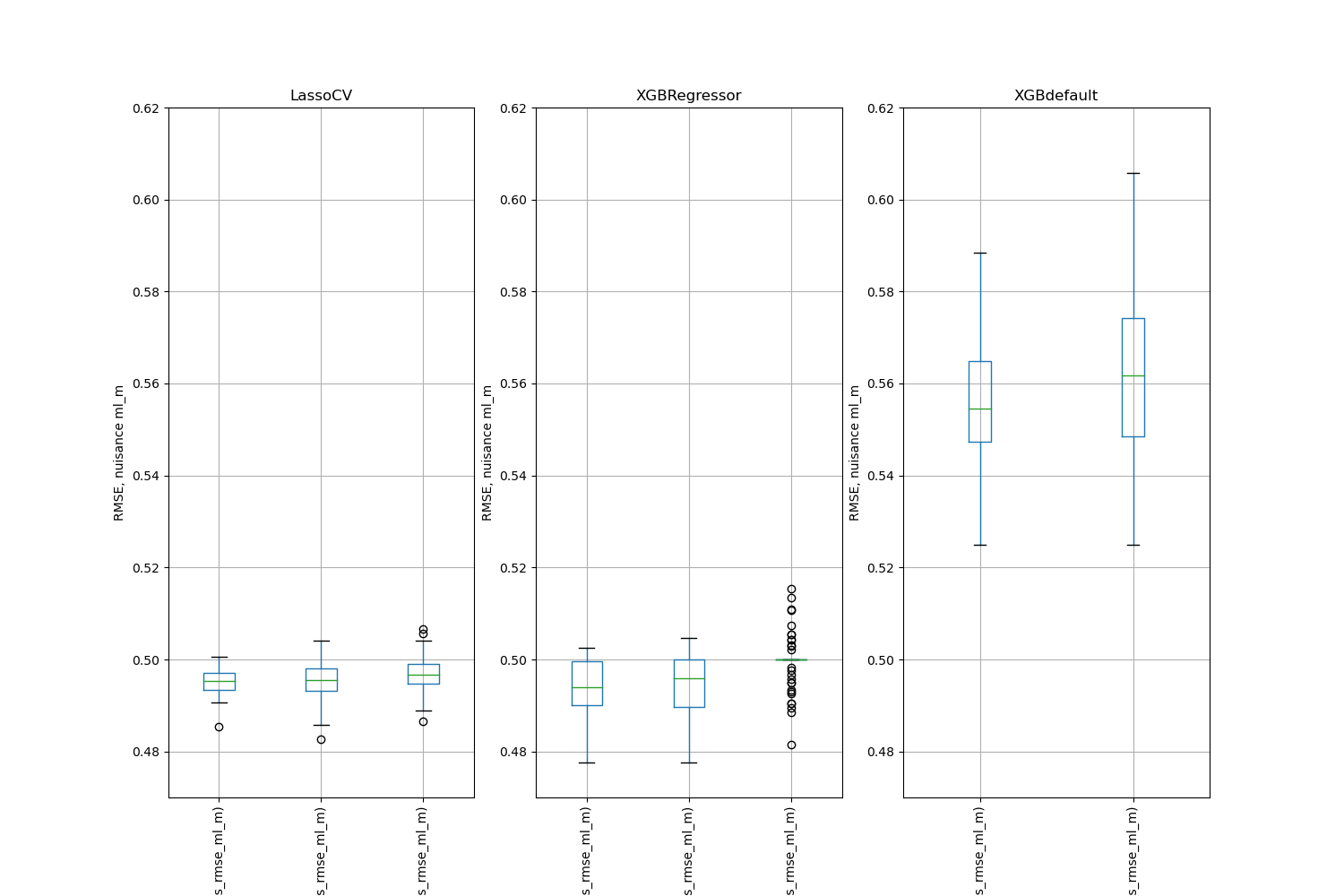
Simulation Results: 2. ACIC (DGP 2)
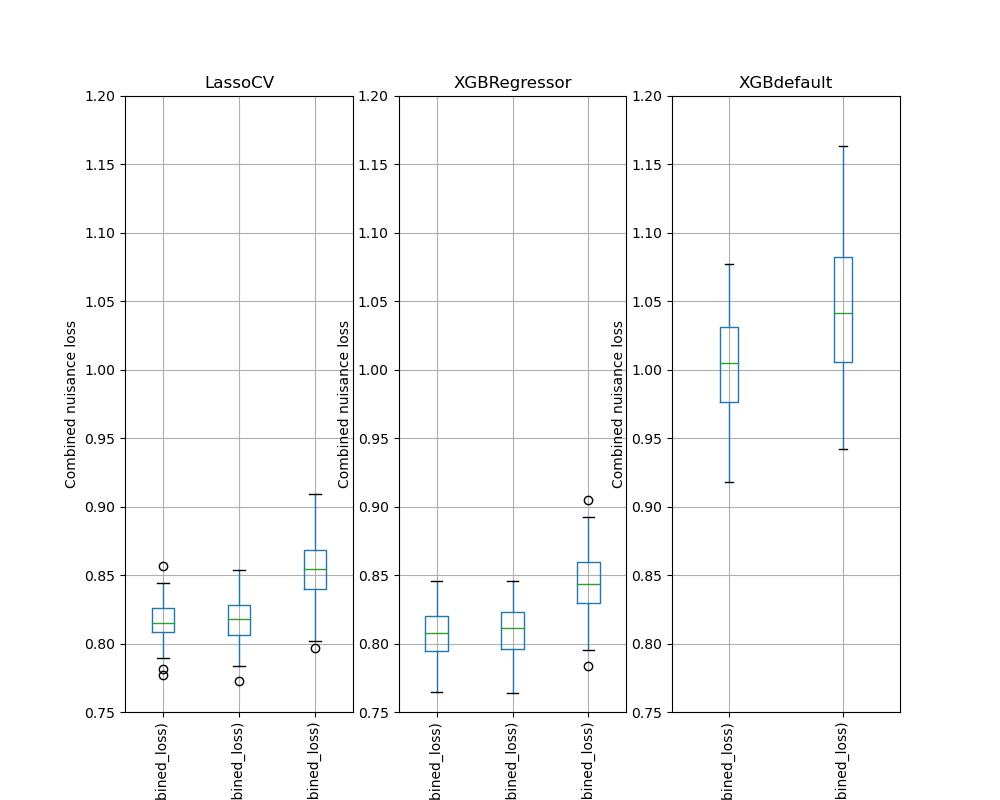
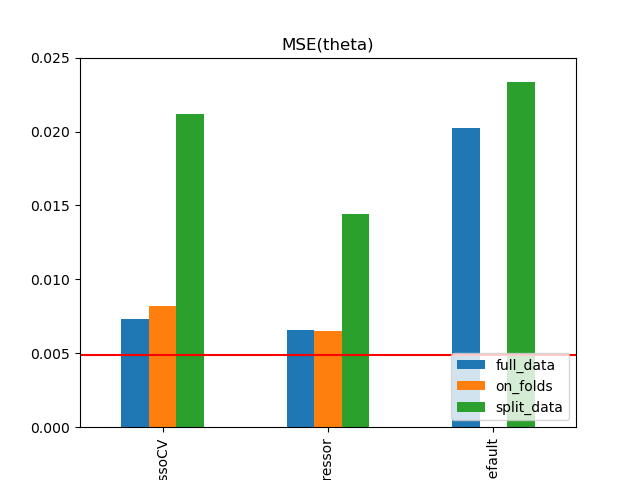
Simulation Results: 2. ACIC (DGP 2)
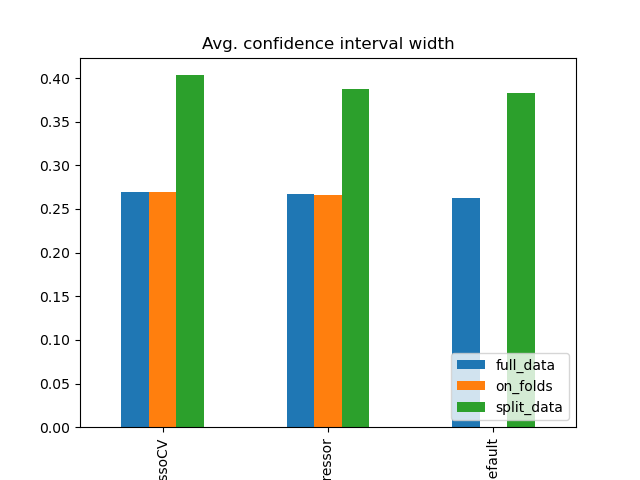
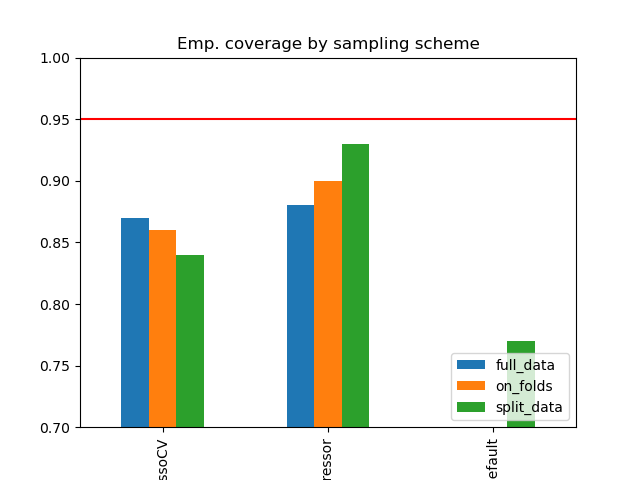
Simulation Results: 2. ACIC (DGP 2)
Number of Folds for Cross-Fitting
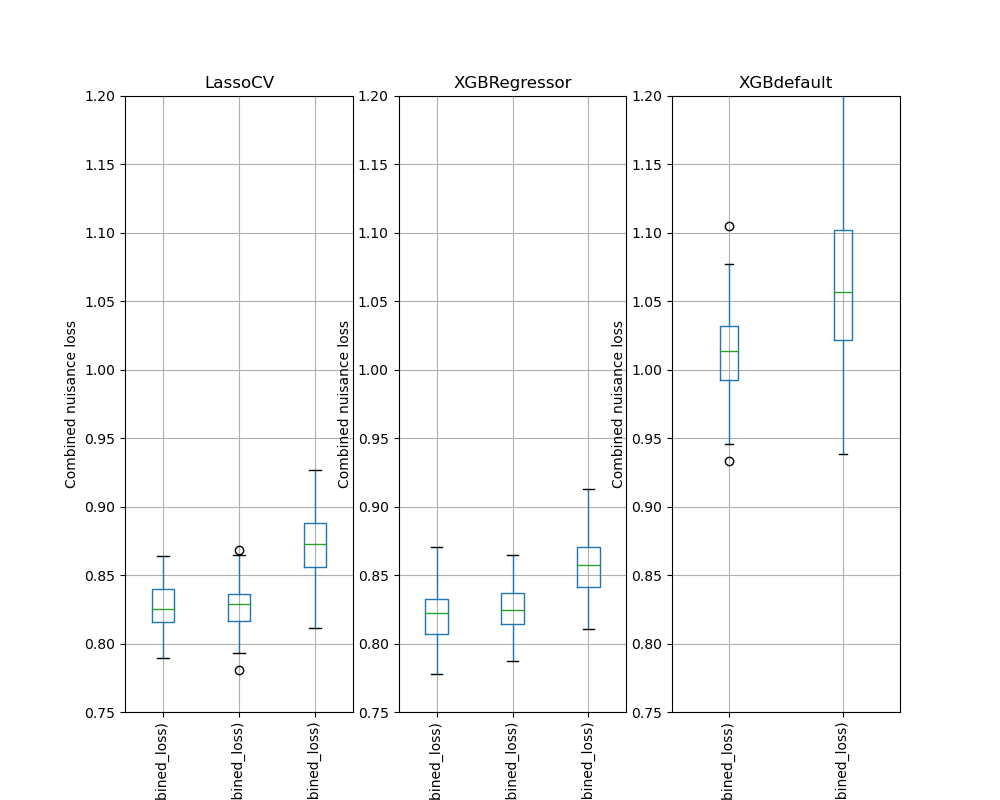
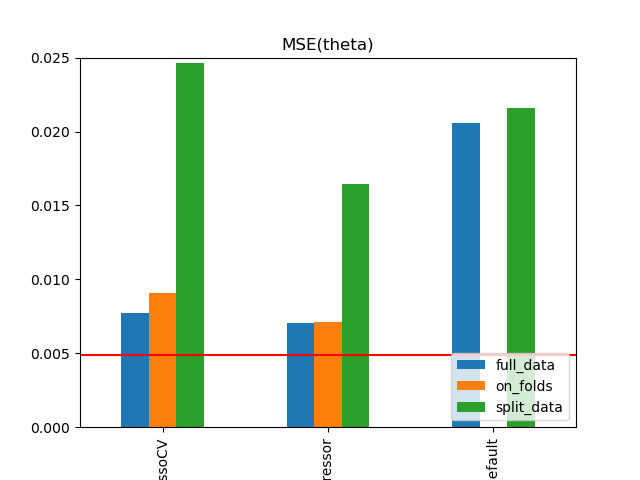
Simulation Results: 2. ACIC (DGP 2)
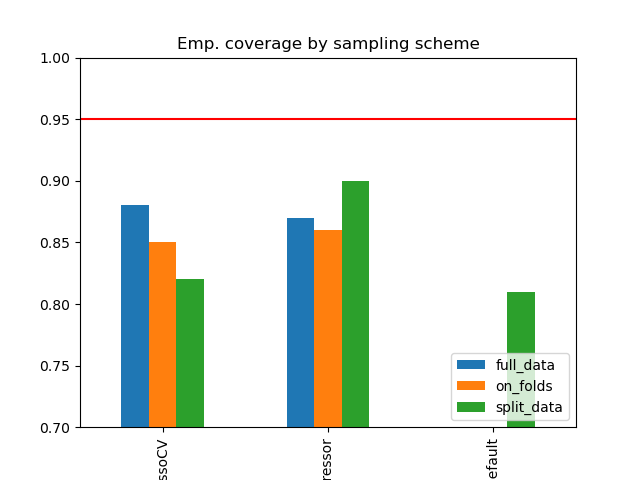
Simulation Results: 2. ACIC (DGP 2)
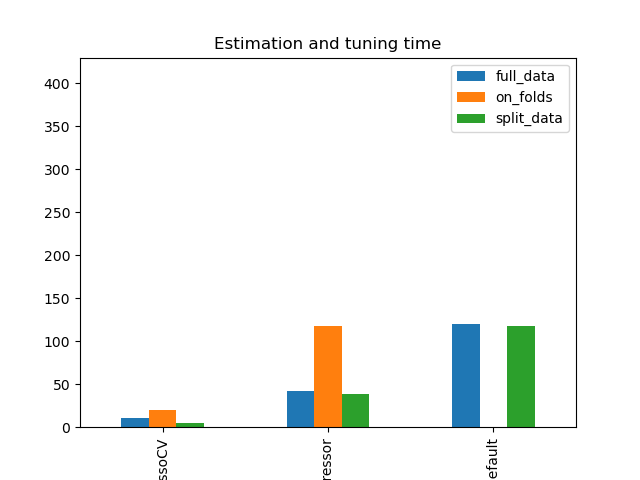
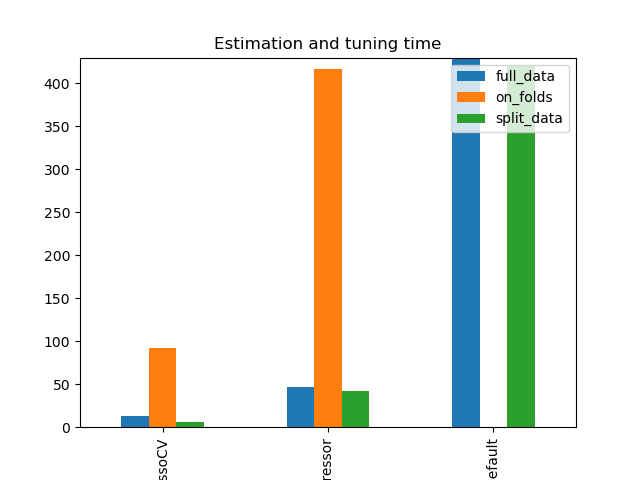
Simulation Results: 2. ACIC (DGP 2)
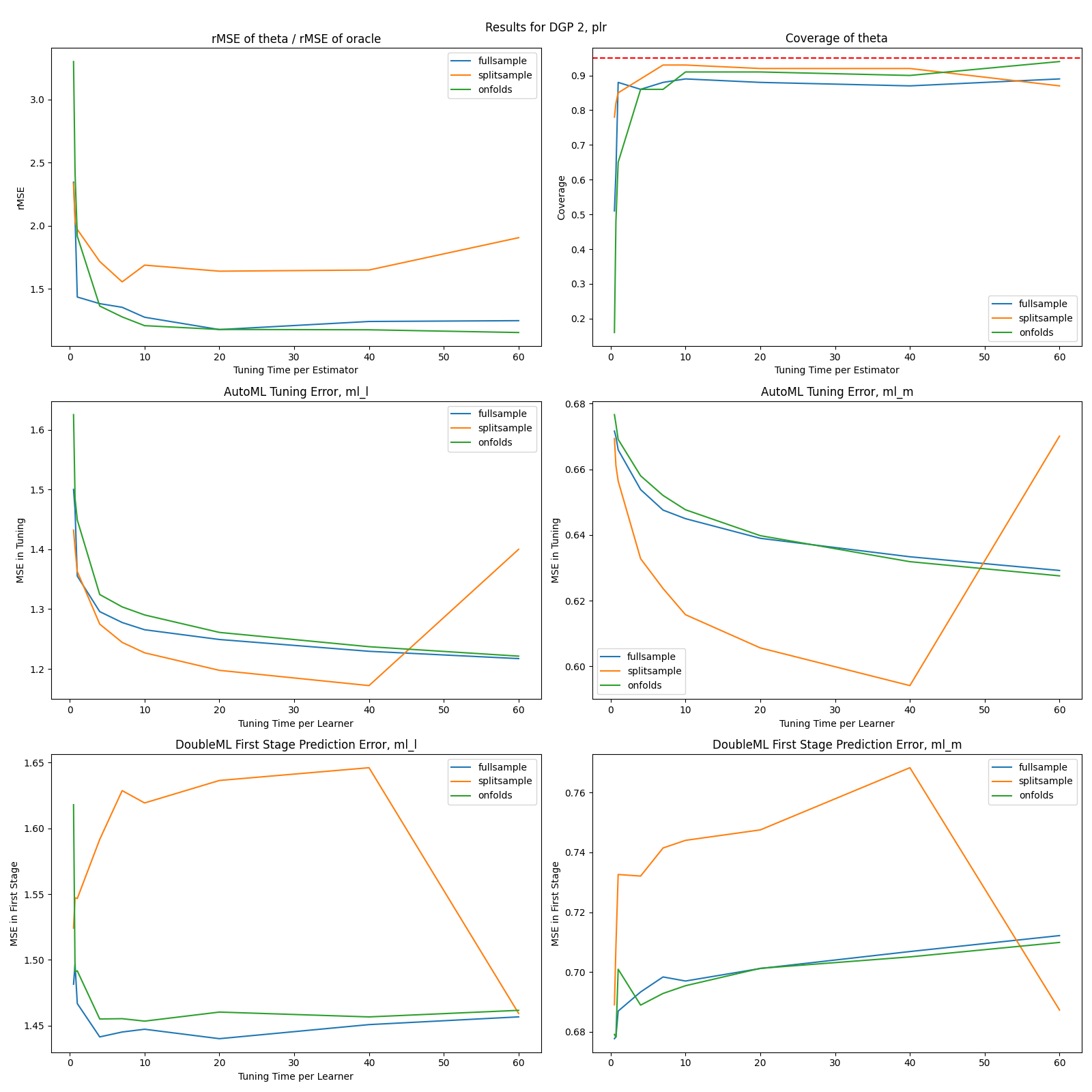
flaml, DGP 2
Simulation Results: 2. ACIC (all DGPs)
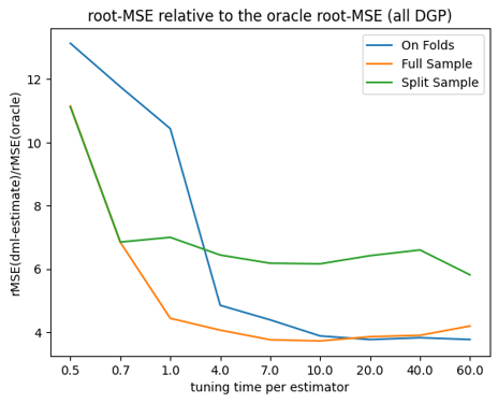
flaml, all DGPs
Simulation Results: 1. BCH 2014
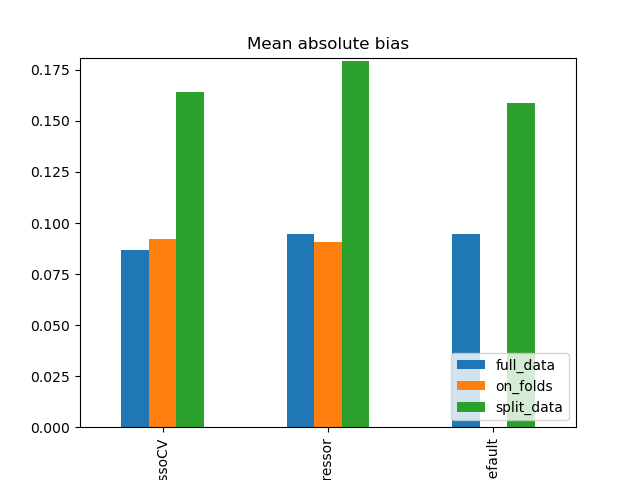
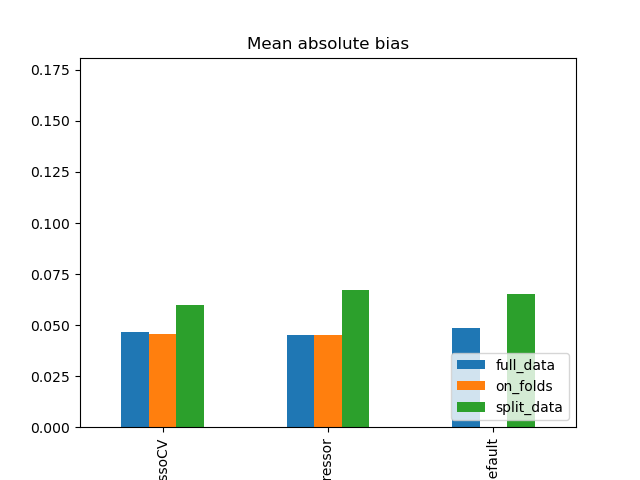
Simulation Results: 1. BCH 2014
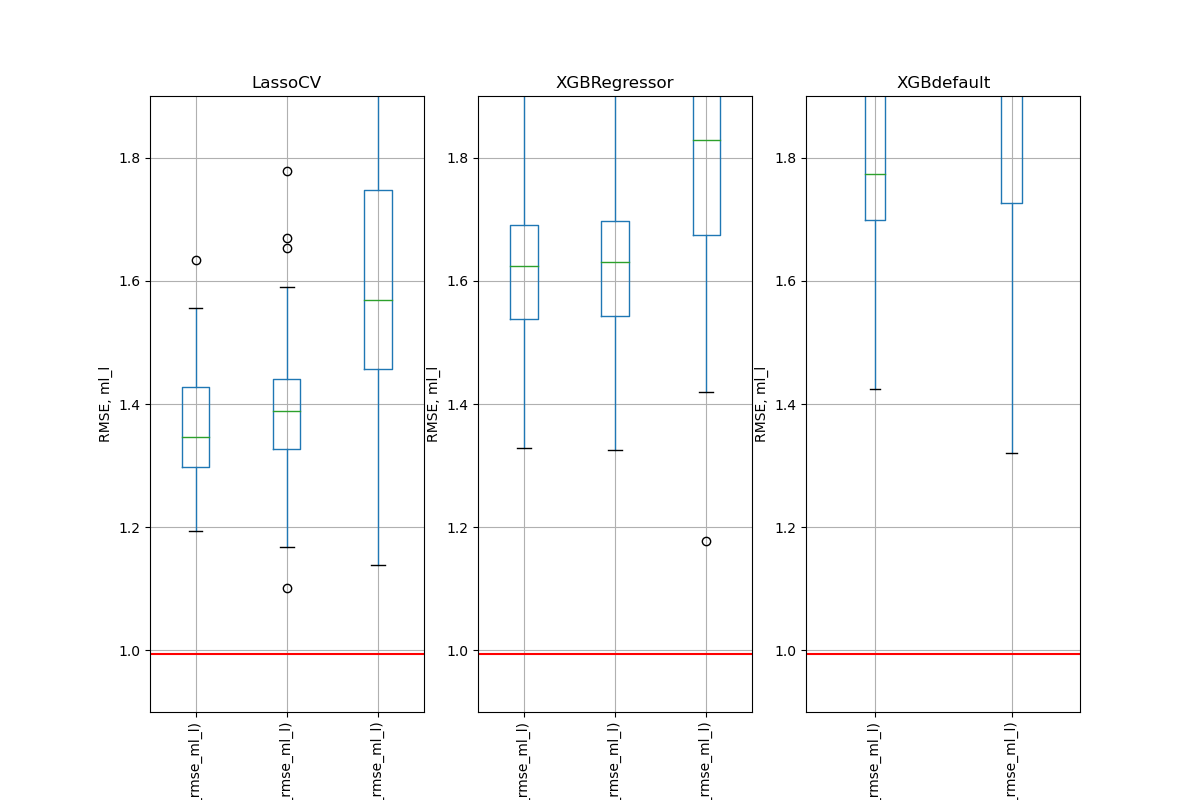
Simulation Results: 1. BCH 2014
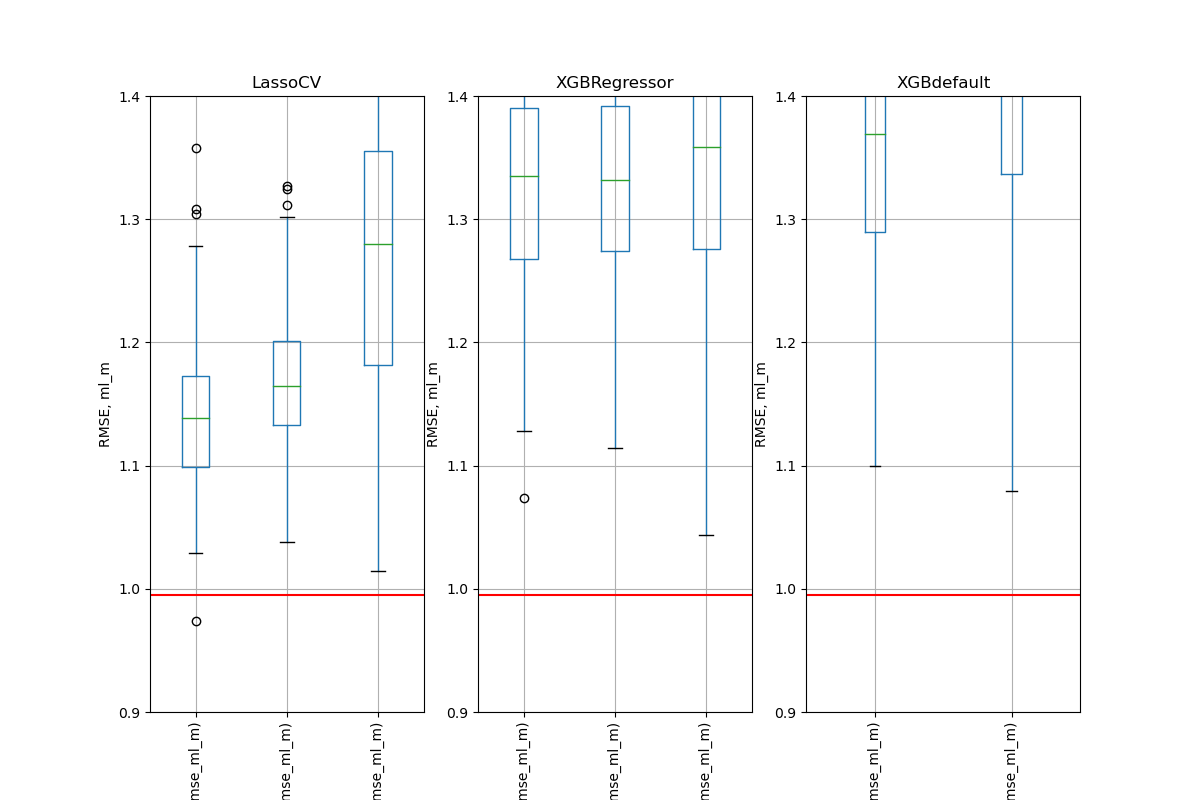
Simulation Results: 1. BCH 2014
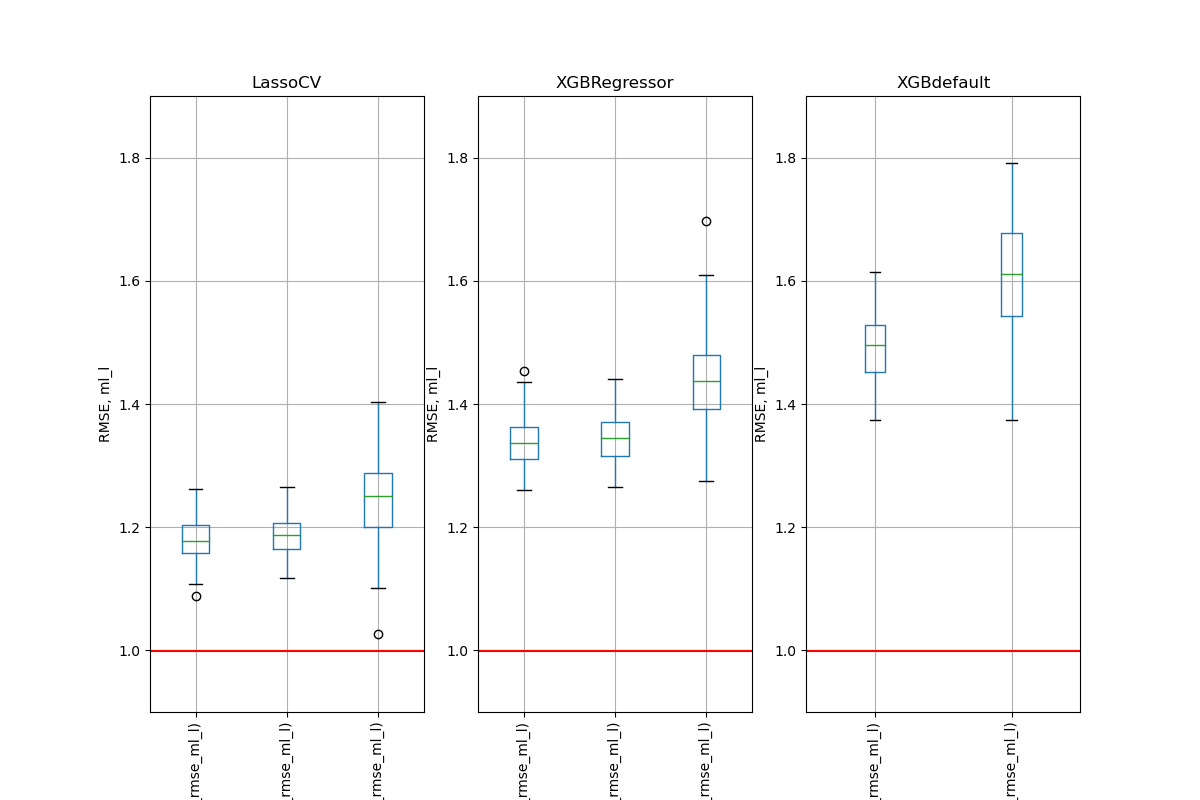
Simulation Results: 1. BCH 2014

Simulation Results: 2. ACIC (DGP 2)
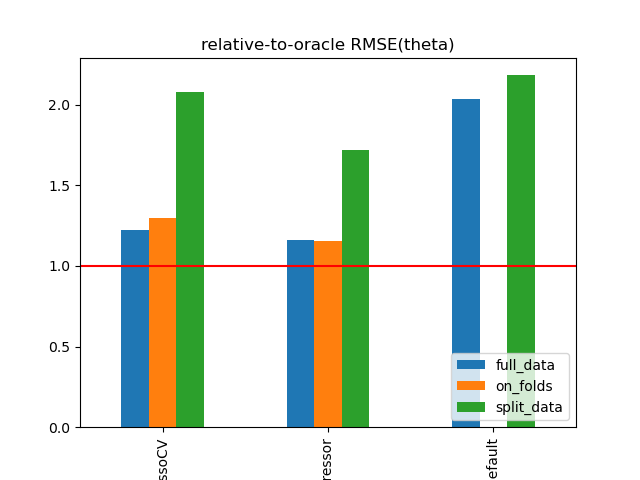
\(\text{rel. MSE}(\hat{\theta}\))
Simulation Results: 2. ACIC (DGP 2)
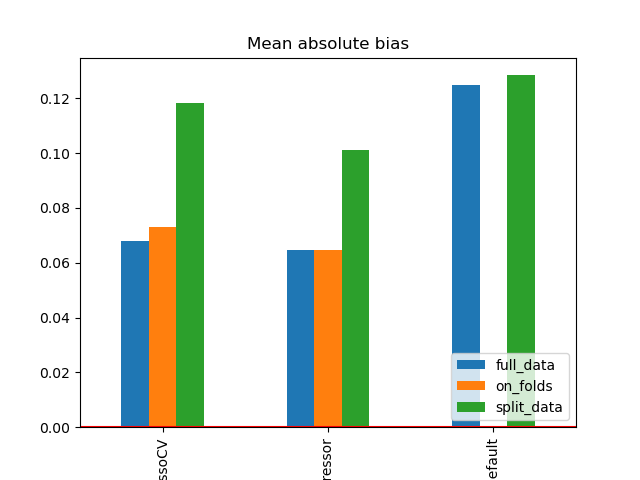
Abs. bias
More resources
For a nontechnical introduction to DML: Bach et al. (2021)
Software implementation:
Paper draft to be uploaded at arxiv soon

::::